Paradigm#
The scio “ruleset”#
The scientific literature on Confidence Scores is very dense and contains many fundamentally different approaches. The main goals of scio are to provide a common framework to ensure fair comparisons between different approaches, while emphasizing real-world applicability. To these ends, we identified \(4\) main points of attention, that together define the scio “ruleset”.
🧊 No model retraining. In many real-world applications, models are either expensive to train, or simply trained by a third party. As such, we only consider approaches able to create confidence scores in a post-hoc fashion. This means that we consider the target models already trained and frozen.
❌ No OoD data. In order to avoid overfitting to specific scenarios, we refrain from using Out-of-Distribution data during the training of confidence score functions, consistently with the novelty detection setup mentioned in Out-of-Distribution Detection.
💧 InD data frugality. Ideally, we would define scoring algorithms that do not require any training data, like the softmax probability. However, the scientific literature shows great improvements when allowing a few InD samples to be used for score design. This is also compatible with a collaborative framework, in which the model provider can share a small proportion of leftover training data, referred to as calibration data. We purposefully do not explicitate the notions of a few samples and a small proportion, which should be comparable to those used in classical validation datasets for Neural Networks training.
⚡ Marginal computational cost. It is important that procedures augmenting predictions with confidence scores do not require too much computational resources. The magnitude of the acceptable overhead greatly depends on the use case, often ranging from a few percents to a few hundred percents.
These “rules” are not formal but loosely define the general spirit.
Implementation#
The rules above ultimately force any compatible approach to leverage the knowledge already encoded by the model. The scientific community achieves this through the analysis of the internal representations (also called latent spaces or embeddings) during inference. In general, we illustrate the working paradigm guiding scio development below.
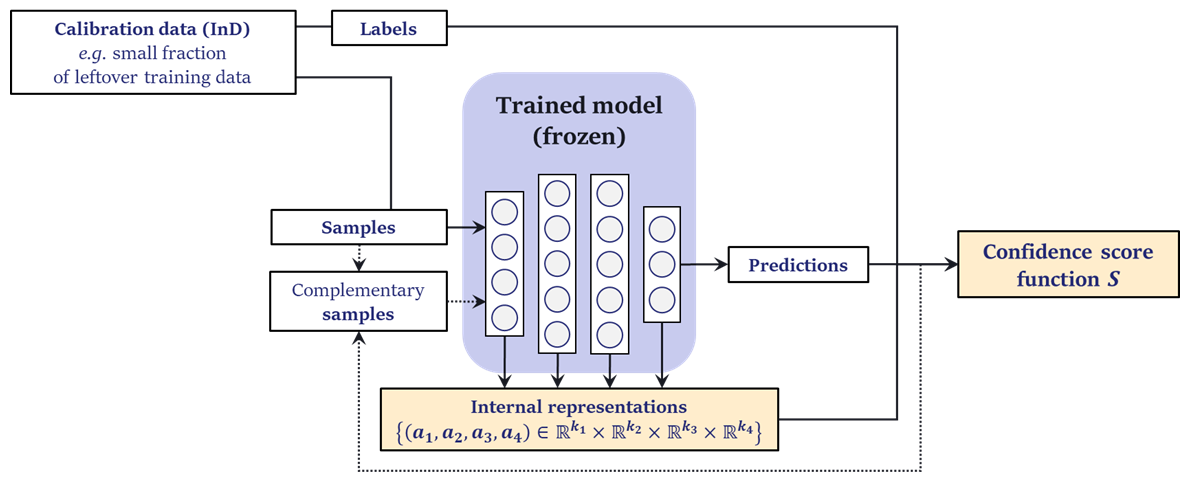
Of course, not all methods implemented in scio use every components of this diagram. In general, think of the complementary samples (optional) as slight modifications of calibration samples: compressed, noised, adversarially transformed, etc… Finally, note that methods may also use gradient-based information with respect to inputs or model weights, undepicted here.